CHAT INTERFACE
Ideation I - Tackle the usability issue of AI-chatbot interfaces
Period: May 2025 - Jun 2025
Challenge: The ChatGPT conversation interface consists of a series of user-submitted prompts and AI-generated responses. Without any deliberate organizational structure, questions and answers gradually accumulate on the main screen under a given topic. When a user asks a dozen or more questions, the thread can easily encompass over twenty individual exchanges. As a result, locating the final conclusions or recommendations—whether in the form of a concise summary or a detailed, point-by-point explanation—can become quite challenging. In most cases, users must manually scroll through the entire conversation or submit an additional “summarize” prompt to have ChatGPT generate a cohesive overview.
Solution: We enable user to generate a summary after any model response and choose which response to be considered in the summary. The default of generated summary covers all the responses in the chat, while user can select specific response that the new summary should take into account.
design concept
Sometimes a conversation can become quite lengthy and encompass multiple dimensions—whether focusing on a single topic or branching into several related subjects. Therefore, when we attempt to revisit a conversation thread to clarify its conceptual flow, we must rely on our own organizational efforts in addition to any assistance provided by the AI. Of course, relying on AI often risks a secondary layer of simplification; however, there are times when we want to faithfully organize the topics or dimensions that truly concern us.
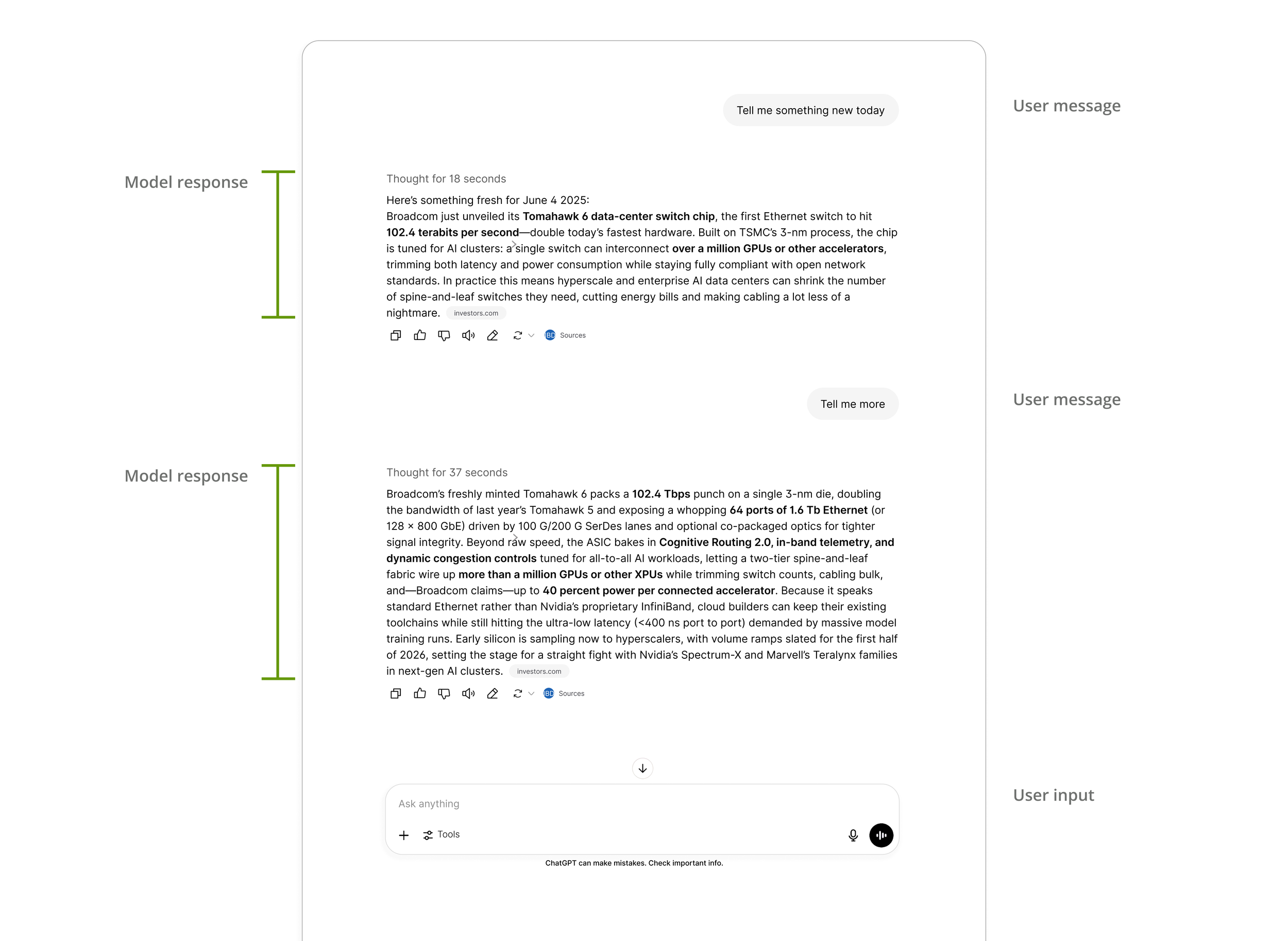
Adopting ChatGPT’s existing interaction model, users can select “Summarize this chat” from the toolbar. The system will open a separate canvas interface on the right-hand side, showing the conversation thread selection at the top (defaulting to include all) and the generated summary below.
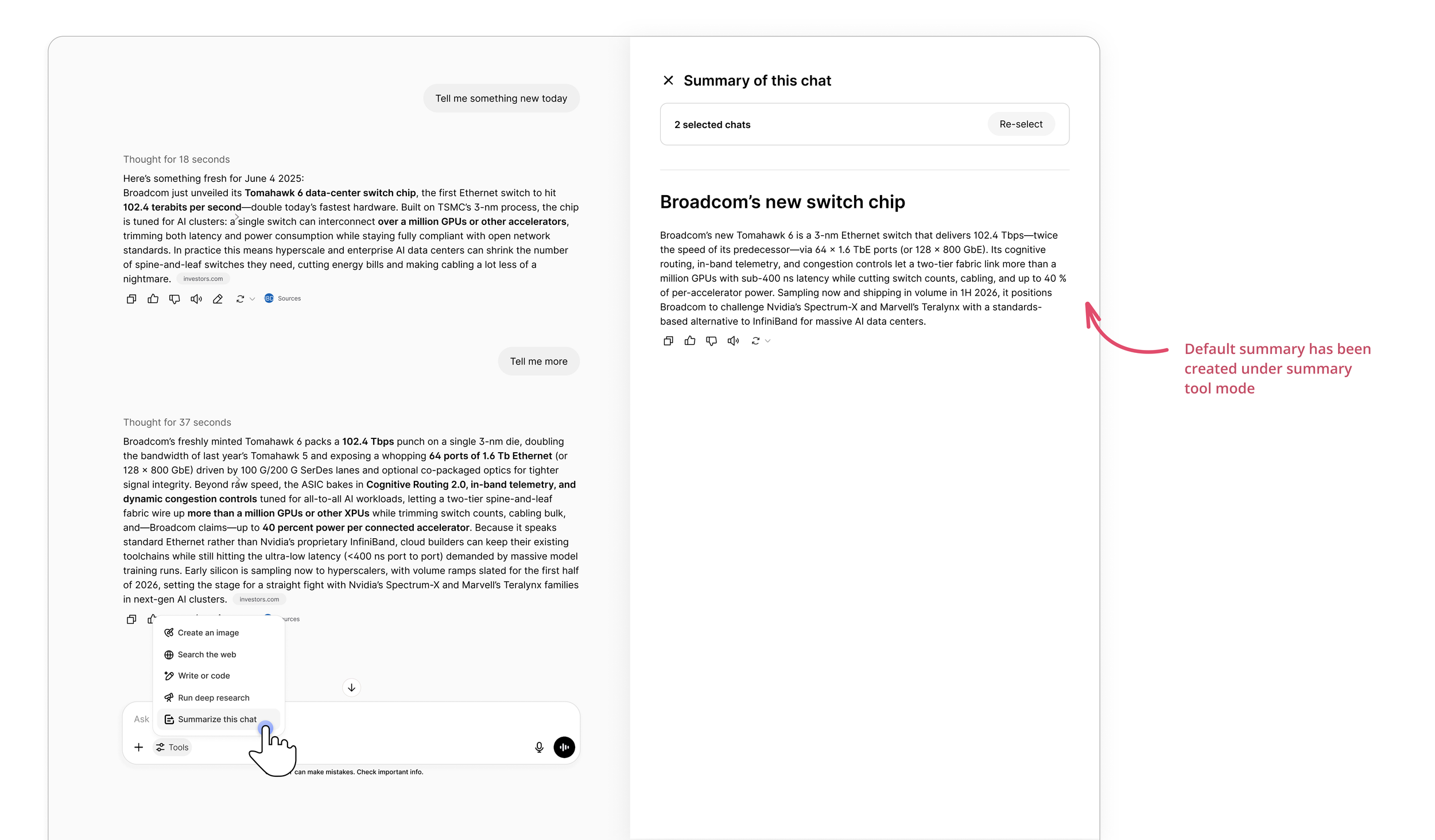
Users can click the “Re-select” button located to the right of the conversation selection area at the top. After clicking “Re-select,” the lower pane will display summary responses spanning the entire conversation history—from the very first exchange to the most recent—so users can browse and filter as needed. If a user wants to revisit a specific portion of the dialogue, they can simply click on that reply in the summary area; the left-hand main view will automatically scroll (“anchor”) to the original message for confirmation. Once the user has confirmed their selection, clicking “Done” will collapse the conversation-selection panel, and the section below—previously used to refine conclusions—will update to show the newest summary, just as depicted in the previous illustration.
Another point to note is that when “Summarize Conversation” is selected as the active tool in the input box, any user input will prompt the model to base its response solely on the existing summary. If the information needed to answer exceeds what the summary contains, the model will ask the user whether to broaden the scope of its response. At the same time, the system will suggest that the user update the summary to include a more complete portion of the conversation as its reference.
How might we
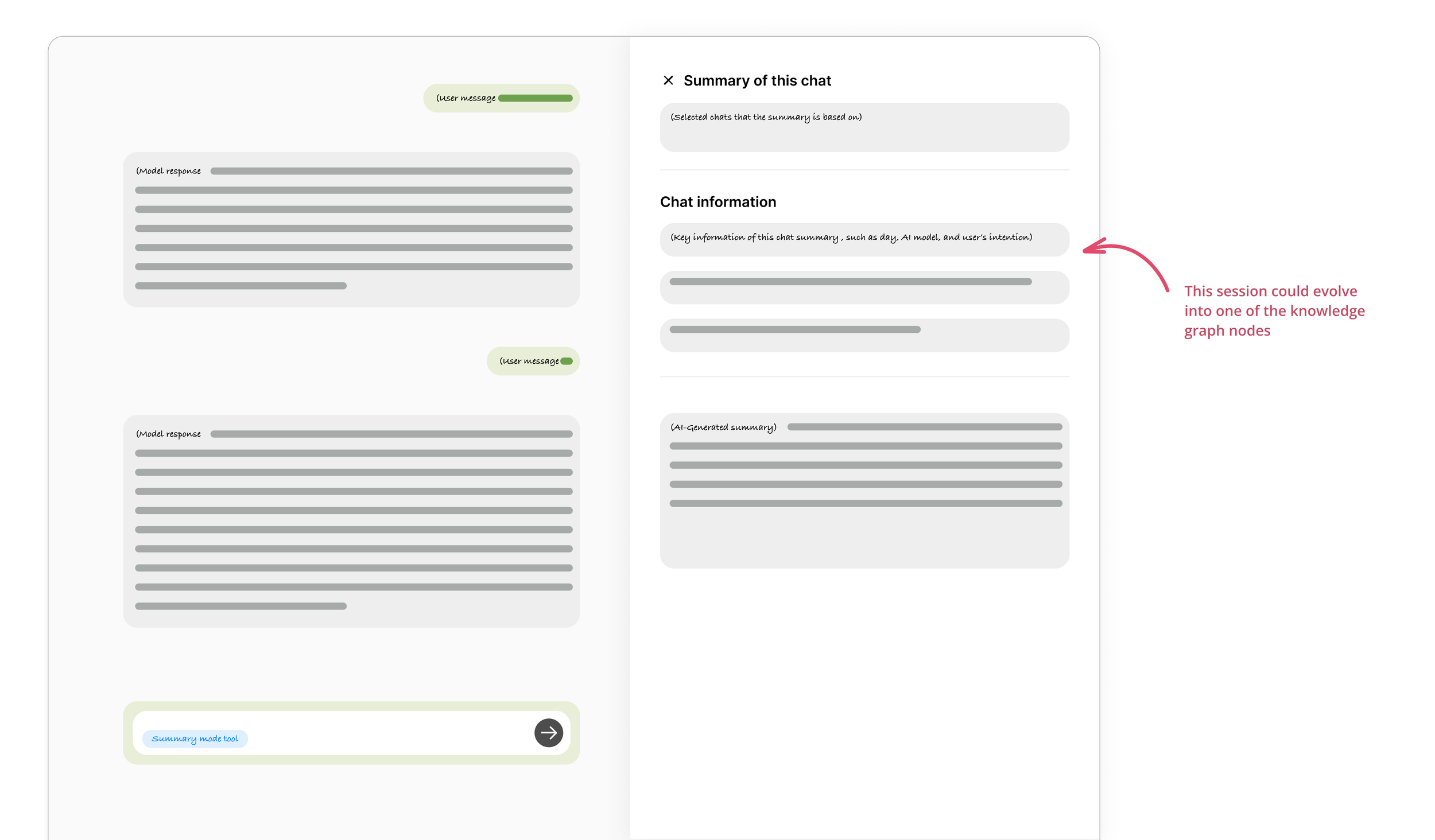
To date, our summary tool generates a concise recap of a conversation thread: when a user activates the summary feature, a canvas panel slides in from the right displaying only the distilled text. But if we pause to consider how users engage with these summaries over time, we realize they often need more than just a text excerpt. They may want to uncover the underlying intent of the discussion, review which prompts were issued, or identify which AI model was invoked. In other words, the full conversational context—not just the summary itself—should be incorporated into the canvas, enabling users to quickly regain their bearings when revisiting past chats.

By empowering each chat a unique characteristic in summary, we can map their interconnections into a richer knowledge graph from “chat” point of view—boosting the AI model’s performance and enabling users to manage information out of conversation more effectively, which also uncover the pattern through the human-AI interaction.
Let me simplify this concept in a low-fi UI style to visualize the layout below.
Ideation II - Customize the content generated by AI
Period: May 2025 - Jun 2025
Challenge: AI-powered multimedia content generation has been explored extensively across various platforms. Prior to developing this second concept, I had not encountered AI tools such as ChatGPT offering similar features. However, I later observed that other tools have since introduced functionalities aligned with my initial idea. Currently, ChatGPT offers the capability to modify objects by selecting individual elements within an image. However, the selection process lacks precision, often resulting in users selecting areas outside the intended target. Additionally, the outcomes do not always align accurately with the prompt. At times, the adjustments apply to all similar objects rather than the specific one desired.
Solution: The concept involves segmenting objects powered by deep learning, within an image, so that each object can be regenerated individually. Additionally, objects not originally present in the image can be created based on the user's prompt. Users have the ability to modify the appearance of each object or apply a specific style provided through an uploaded reference.
Deisgn concept
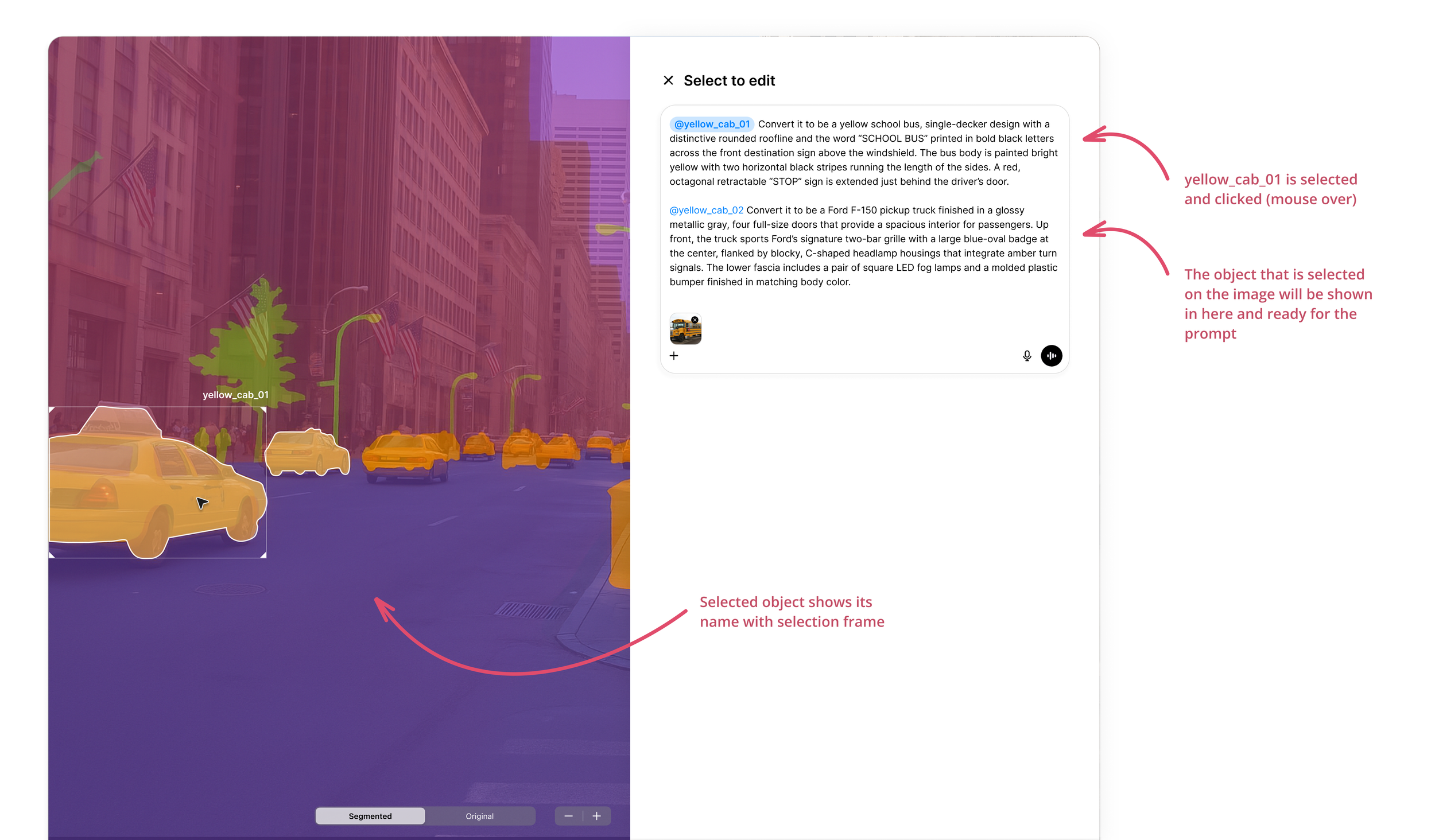
When ChatGPT generates an image, the user can click on it and select the "Select" tool at the top. They can then color the area of the image they wish to modify. After entering the prompt, the user waits for the AI to regenerate the desired results. User can select one or more areas for the prompting.

This image is re-generated by ChatGPT so might look slightly different from the original one down below.
In this case above, I prompt:
- Change the taxi car to be a school bus.
- Change the trash car and the street light to be a traffic light.
- Change the USA flag to be a UK flag.
The areas I select vary in semantic complexity. Ideally, AI should accurately identify the objects I specify in my prompt. However, this is not always the case. The AI achieves approximately 85% accuracy but often incorrectly applies the same classification to similar objects. For example, in the attached image, all the cabs are misidentified as school buses, and all the flags are incorrectly labeled as UK flags, while the traffic lights are all over, which does not align with my intended selection.

Image segmentation is one of the key applications in the Computer Vision domain, where AI can tell the difference of the objects in the image, and allow people to extract out the specific element in pixel to assign the prompt. The image below shows how segmentation looks like powered by AI vision technology.

This image is the original one and credited from https://viso.ai/deep-learning/image-segmentation-using-deep-learning/
The degree of semantic coverage can be adjusted; for instance, each instance of "cab" may refer to different vehicles. In this design concept, user selects couple of distinct objects, for example, two cabs at the left hand side of the image where we can try to prompt with what we want them to be.
Any area or object can be selected, provided that the semantic AI can distinguish it from others. This allows us to easily modify the selected item by tagging it and assigning it a different attribute or category as desired.
how might we
Let us explore this scenario further. With enhanced image segmentation capabilities, it would become possible to manipulate individual parts, components or texture of an object to create entirely novel forms, effectively inventing new products from scratch. This process could integrate principles from physics, aesthetics, modern art, and the knowledge of industrial revolution era as foundational references, or alternatively, generate innovative designs through experimental approaches, presenting challenges yet to be undertaken by others.
The initial layer of the interface may appear complex due to the numerous underlying layers involved. However, this challenge can likely be addressed through natural language processing (NLP) with the assistance of an AI-driven system to support structural organization and implementation. To maximize its effectiveness, the AI must be trained on extensive real-world data, serving as a comprehensive knowledge hub that continuously adds meaningful value to our work.
Returning to the interface, the relationship between humans and digital (as well as moving) objects still has significant room for development. Up to now, we've primarily managed to advance the informational layer, which assists in making informed decisions. In the realm of AI, there could be a conceptual equivalent of a mouse cursor, allowing seamless navigation through bits and bytes. However, that is perhaps a topic for another time.
Ideation III - Chat reasoning Interface
Period: May 2025 - Jun 2025
Challenge: When posing a question to a large language model such as ChatGPT, users typically receive a response in a single format unless additional clarification is requested. Ideally, the AI should be capable of discerning which format would be most beneficial for the user based on the query. In such cases, the interface could present a response organized into multiple well-defined formats, clearly outlined and accessible at the outset.
Solution: When responding to a user's prompt, whether it is a question or a statement, ChatGPT should be capable of analyzing the input and providing thoughtful, appropriate, and well-reasoned answers. This response may incorporate various media formats to enhance the user's reasoning capabilities. Maybe the AI would consider the information hierarchy, or the task priority, to layout the pieces of digits into a more comprehensible way of learning. By following this manner, the thinking process of how AI makes a move step by step interactively, might will be a valuable assets for people to make a better decision.
Design concept
Before proceeding, let us examine how ChatGPT and Perplexity— the latter aligning more closely with the concept I am seeking—address the situation described above. Here is the prompt I wrote, and this is the one that I happen to see from the Project CityAI, conducted by City Science Lab at Taipei Tech.
“I am a private developer for elderly-care village. I am looking for locations within 15-minute drive from high-speed rail stations in Taiwan. Please help me analyze potential locations”
The primary focus is not on the AI-selected final location. Rather, by examining the sequential steps within the conversation interface, we can observe how data and information are gathered.

Let’s see another case of how Perplexity shows the result in the reply.
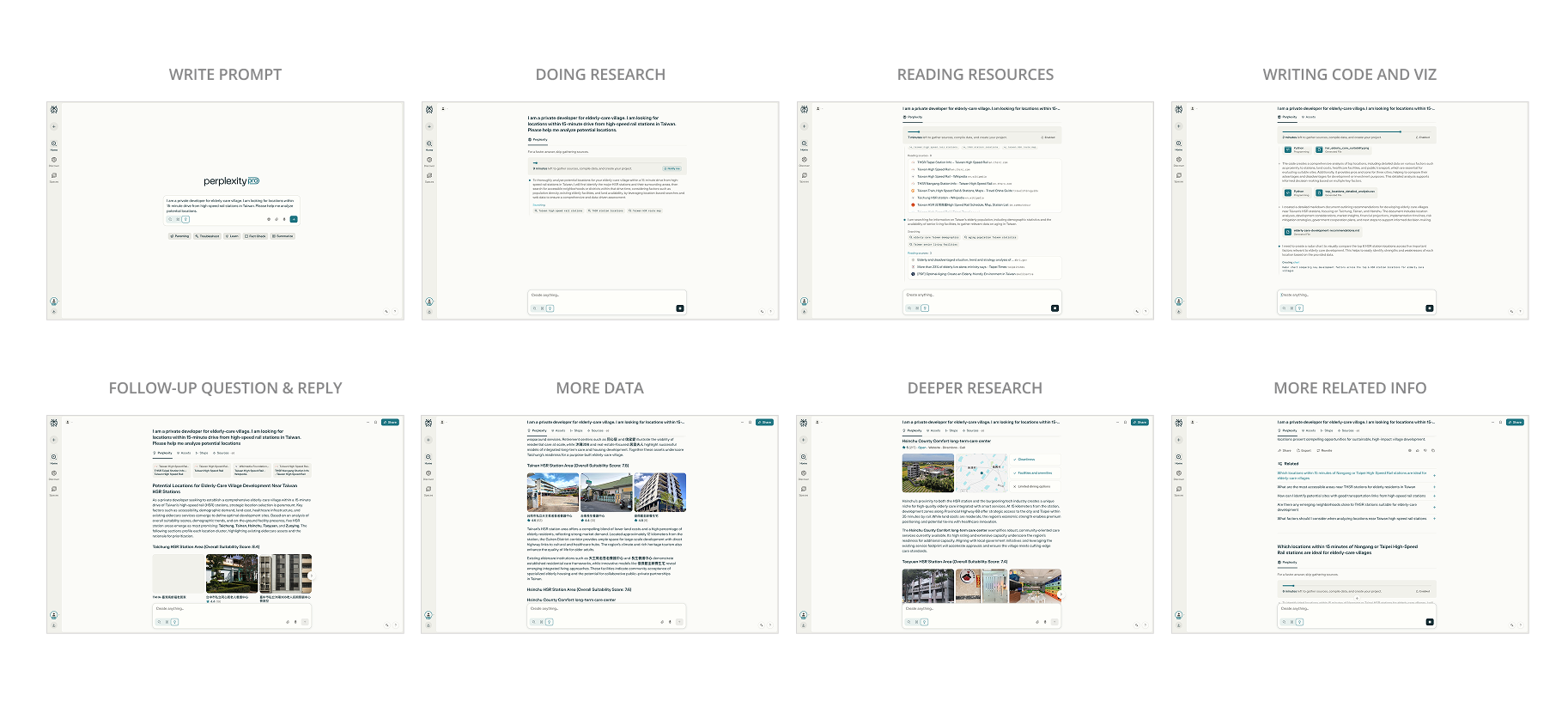
Perplexity progressively displays the information it retrieves, offering comprehensive and paired questions and answers to facilitate deeper exploration. Additionally, it supports a wide range of data formats beyond plain text, including code, data visualizations, social network pages, and maps, where you can see under the Assets.
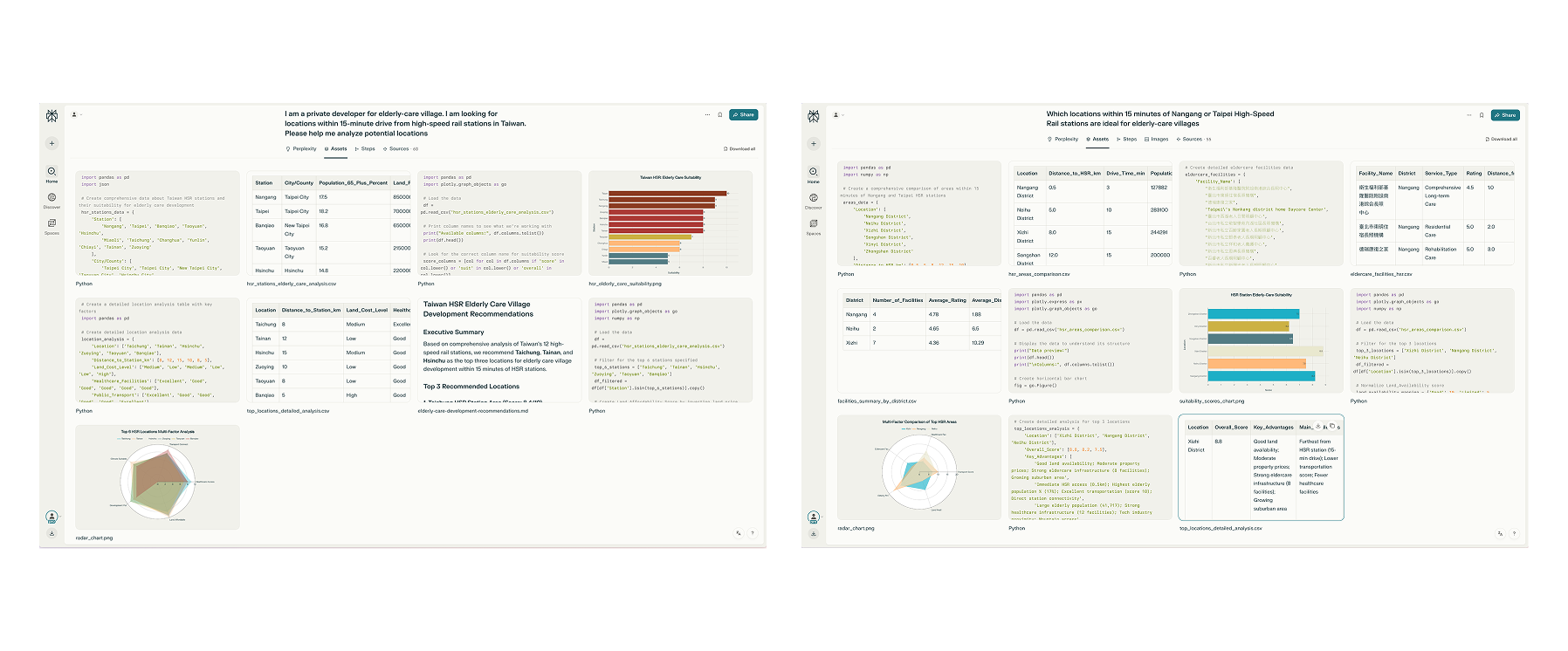
Based on this concept, how could we tweak ChatGPT’s interface design, so that we won’t be passively just by reading the reply texts to imagine or interpret the meaning? In both cases above, they have one thing in common, which I think most of the LLM applications might have, is the AI thinking process flow. That line of thinking could be sometimes running for minutes or seconds. AI should take advantage of this capability and show off to user in their reply as well as know what information that user might will be interested in terms of the question asked.
In this case, there are several aspects that users may be interested in and wish to adjust, including parameters related to data analysis. These could involve a map overview featuring Taiwan High-Speed Rail alongside elderly care statistics, as well as data comparisons with scoring metrics or images of the locations, among other elements.
The core concept is that when AI responds, it can include supporting materials based on an analysis of the prompt, the response content, context, and the user's intent. This approach enhances user understanding by selecting the most appropriate format—such as a video when visual demonstration is beneficial, or a chart when it conveys more information than extensive text.
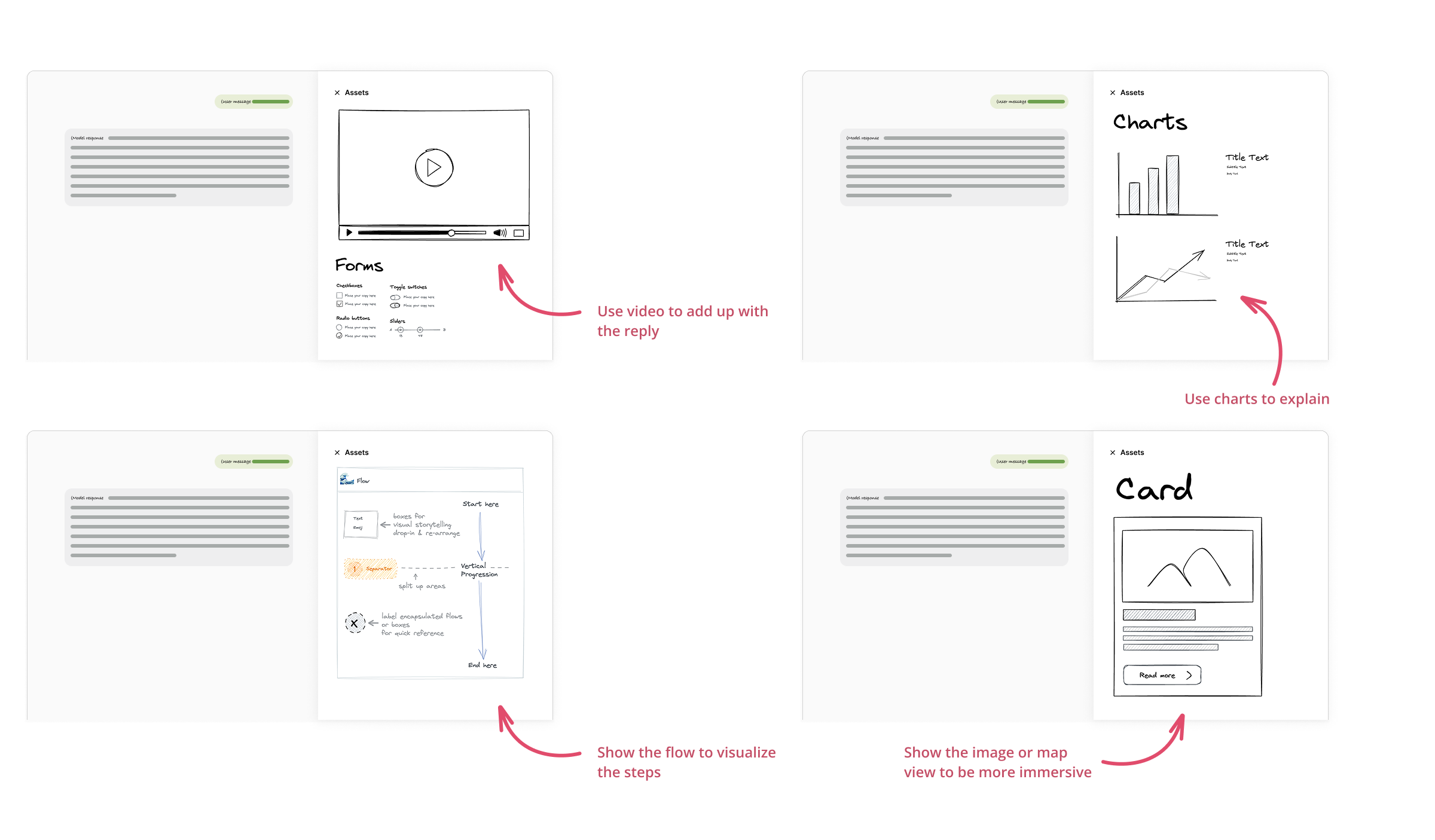
One more step
Referring back to the original proposal, we could provide users with an interactive tool panel that enables dynamic engagement. For instance, the prompt involves rail stations across various counties; therefore, designing the interactive dashboard on the right with adjustable parameters would allow users to input or modify information directly (by changing station’s name for example). This approach would eliminate repetitive question-and-answer cycles, as users would only need to change the keyword for all related data to update automatically.
Wrap Up
The ChatGPT interface consists of numerous separate chat threads, which may not fully align with conventional cognitive processes. Not all information is effectively conveyed through text or visualized using mind maps. When the core intention remains unclear, alternative approaches can be explored to determine which direction yields greater satisfaction and aligns with the desired objectives. Beyond the AI generation environment as a playground, existing resources also provide valuable insights that can be applied to product development.